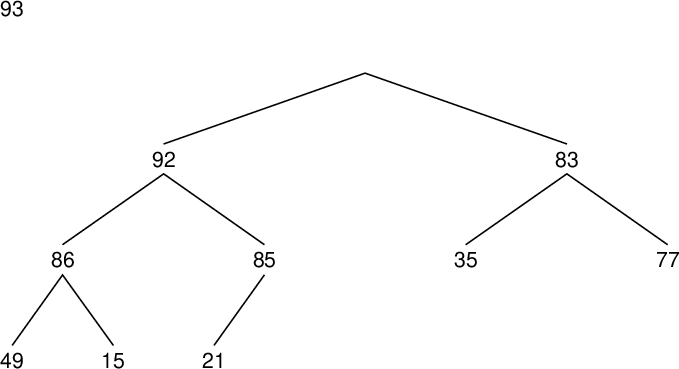
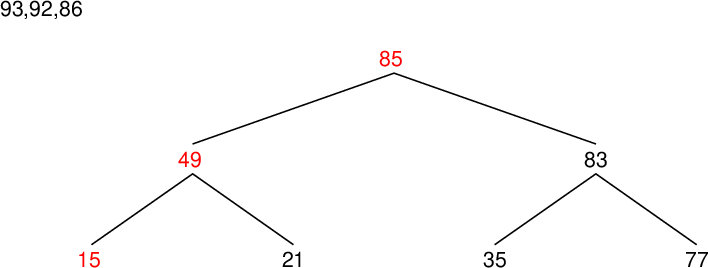
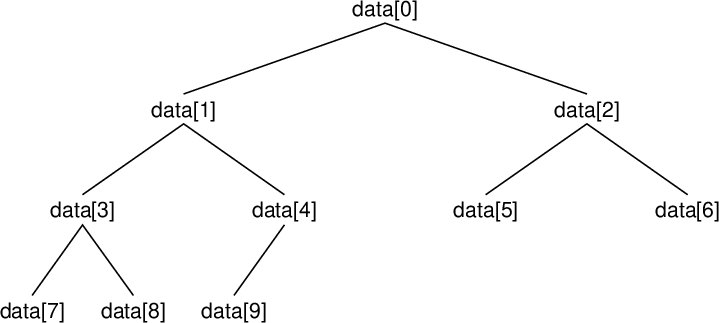
| 配列要素 Array component |
値 Value |
| data[0] | 83 |
| data[1] | 85 |
| data[2] | 77 |
| data[3] | 15 |
| data[4] | 93 |
| data[5] | 35 |
| data[6] | 86 |
| data[7] | 92 |
| data[8] | 49 |
| data[9] | 21 |
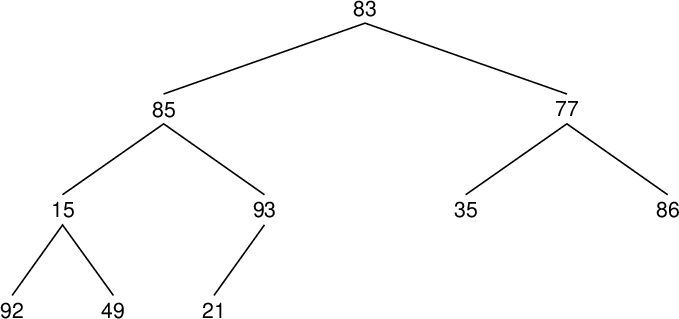
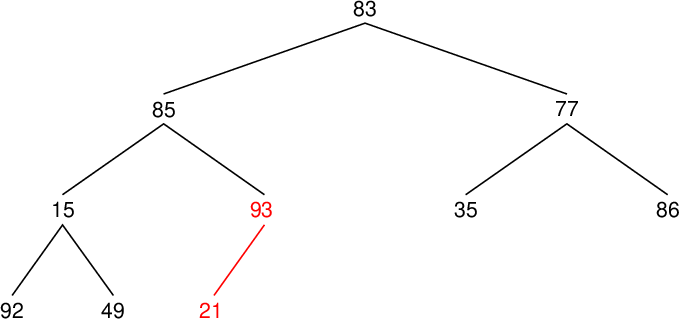
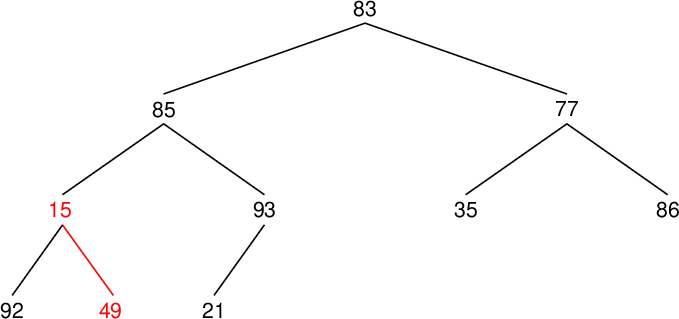
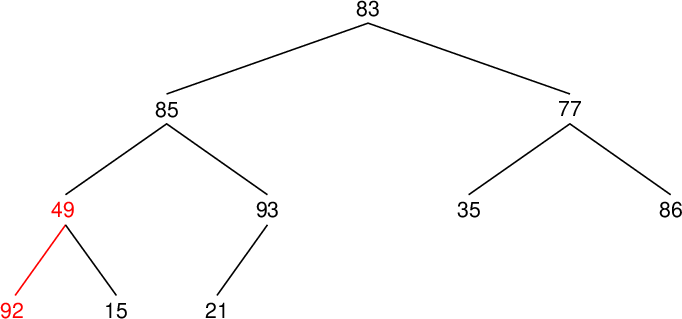
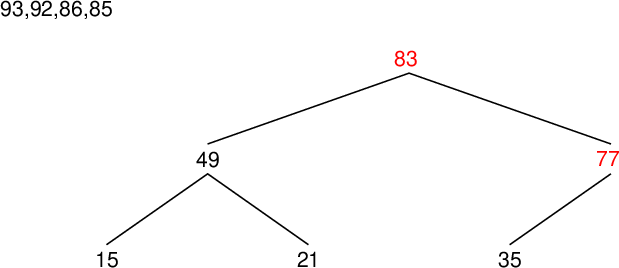
| 配列要素番号 Array component index |
値 Value |
親要素の値 Value of parent component |
置換の有無 Whether to replace (○) or not |
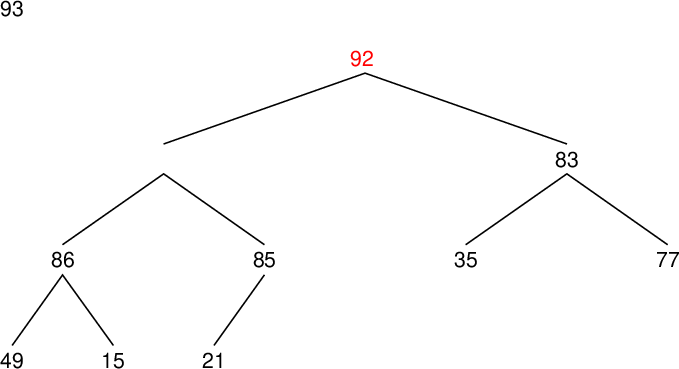
| data[9] | 21 | 93 | |
| data[8] | 49 | 15 | ○ |
| data[7] | 92 | 49 | ○ |
| data[6] | 86 | 77 | ○ |
| data[5] | 35 | 86 | |
| data[4] | 93 | 85 | ○ |
| data[3] | 92 | 93 | |
| data[2] | 86 | 83 | ○ |
| data[1] | 93 | 86 | ○ |
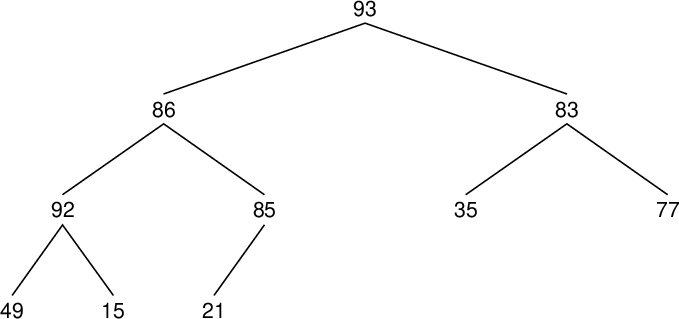
| 配列要素番号 Array component index |
値 Value |
親要素の値 Value of parent component |
置換の有無 Whether to replace (○) or not |
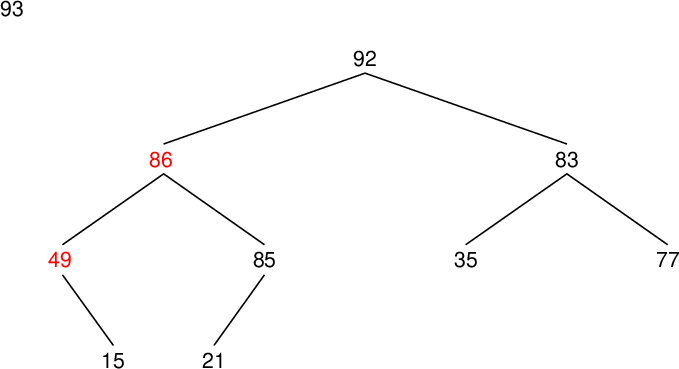
| data[9] | 21 | 85 | |
| data[8] | 15 | 92 | |
| data[7] | 49 | 92 | |
| data[6] | 77 | 83 | |
| data[5] | 35 | 83 | |
| data[4] | 85 | 86 | |
| data[3] | 92 | 86 | ○ |
| data[2] | 83 | 93 | |
| data[1] | 92 | 93 |
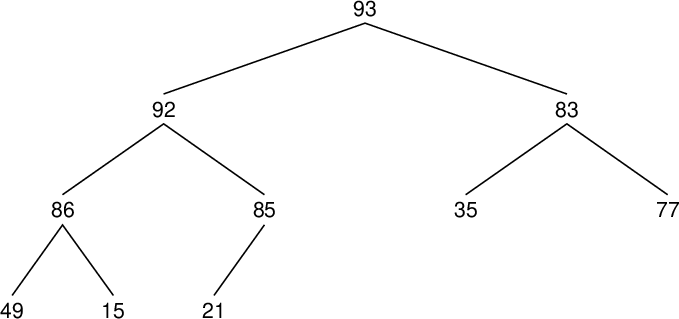
| 配列要素番号 Array component index |
値 Value |
親要素の値 Value of parent component |
置換の有無 Whether to replace (○) or not |
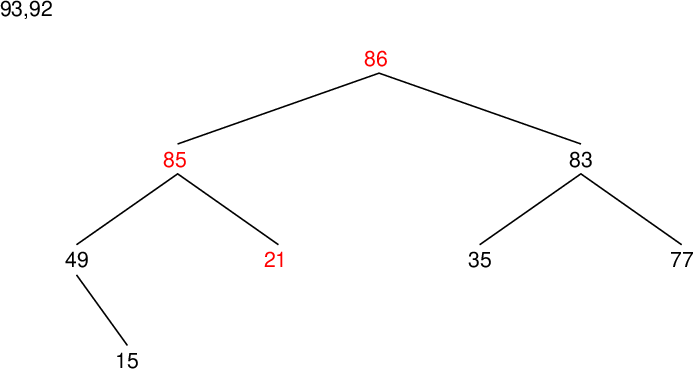
| data[9] | 21 | 85 | |
| data[8] | 15 | 86 | |
| data[7] | 49 | 86 | |
| data[6] | 77 | 83 | |
| data[5] | 35 | 83 | |
| data[4] | 85 | 92 | |
| data[3] | 86 | 92 | |
| data[2] | 83 | 93 | |
| data[1] | 92 | 93 |